An approach: Solving PII detection in Unstructured Data with AI/ML

Teck Wu — 4/4/2023 — 3 Min Read

Challenges in Unstructured data
A lot of PII is contained in unstructured forms of information and communication in any organization. A major challenge here is the format of these communications are informal most of the time. As a result the traditional approaches of identifying PII becomes a challenging task. Standard regular expressions are constrained by their coverage as it depends on rules and corpus mapping. The off the shelf machine learning approaches are also tuned to formal grammatical text and hence they don't perform well with informal texts. Owing to fewer PII in every document it is also a challenge to build solutions which can effectively detect PII without detecting a lot of false positives.
How we are leveraging AI/ML for detections
As we are dealing with mostly informal text we are refactoring the off the shelf named entity recognition models to perform for our data. We are using state of the art language models like BERT to train models to detect PII from unstructured text. We are able to detect Person and Cities with approximately 98% accuracy in customers data. The way we achieved this was a combination of data augmentation and automated annotation followed by changes in traditional model training techniques using approaches like resampling and data annealing.
- Data Augmentation: With limited data available to us in formats of interest we had to augment the data to train our models. The additional challenge was to annotate a large corpus of data with minimal manual oversight. We annotated a small corpus manually and used some off the shelf models. After that using them as entities of interest we randomized their position in the documents of interest and also randomized their values with information from a global corpus. (We were able to augment our a small size of templates by a factor of M*M was determined based on our data requirements towards training). We also augmented the data with some available open source data for using a combination of templates of interest and general data corpus in our downstream training tasks.
- Resampling: With the majority of Named Entity Recognition and Classification models suffering from class imbalance issues, which was extremely prevalent in our case a resampling technique was used to under sample the entities of no interest. The idea behind the method was to select which negative samples to remove by considering their position with respect to positive samples. A parameter R which is the ratio of Positive Samples to Negative Samples was iterated over in the training phase to find the best R which results in the highest level of precision and recall of the models trained on our data.
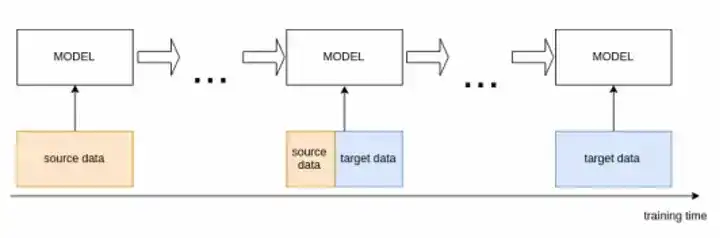
- Data Annealing: With the resampling increasing the percentage of entities of interest in our data, we used another additional technique of data annealing in the training phase. Its a transfer learning procedure that adjusts the ratio of the formal source data and the informal target data from large to small in the training process to solve the overfitting and the noisy initialisation problems.
Steps Ahead:
Presently we are training in-house models and deploying them to customers. Gradually we would move to an on premise model training and deployment using concepts of federated self supervised learning where in an initial base model is deployed and subsequent models are trained individually at customer side with minimal intervention from Borneo.
Contributor: ML Team @ Borneo
What is Borneo?
Borneo helps security & privacy teams achieve continuous compliance and data protection through accurate & actionable data discovery.
Want to watch Borneo in action? Request a demo here and we will get back to you soonest.
Similar Posts

Remote Work @ Borneo (from day 1)
Teck Wu — 3/28/2023 - 6 Min Read

10x Engineer — Learning your tools and other hacks
Teck Wu — 4/3/2023 - 7 Min Read

Privacy Observability — Why Is It Needed Urgently?
Teck Wu — 4/4/2023 - 4 Min Read
Choose real-time data protection. Choose Borneo.
Manage risk, increase trust, and accelerate innovation across your entire data ecosystem.